Pi
Day 2018 –PrIme Numbers and PI
Anyone
who studies even a bit of advanced mathematics soon discovers the fact that the
number pi (3.14159…) shows up all over the place. Sometimes that seems fairly easy to
understand - e.g. the unit circle is fundamental to trigonometry, so it seems
natural that pi should show up there. Other times, it seems more mysterious – for
example, number theory is concerned with prime numbers, which are integers, so
why does pi show up so often in that subject?
But it does.
Anyway,
here’s an example from a book that I own, called “Recreations in the Theory of
Numbers”:
If you take any two random numbers and compare
them, the probability that they are relatively prime turns out to be = 6/pi**2.
I won’t
bother with a proof of this claim – no doubt you can find a reference on wiki or
some other source. But I did think it
would be interesting to test it experimentally, so to speak.
This was
a lunch hour exercise at work, so I relied on an Excel hack. No doubt a more elegant method could work
better and would be more robust. Here’s
the method:
·
- First, I set up a spreadsheet model, with two
random numbers between 1 and 200.
- Then, I then tested all of the numbers between 1
and 100 with the modulus function, to see whether they divided evenly into the
random numbers chosen.
- If the two numbers had a common divisor, I noted
that. Basically, if the sum of any given
modulus of the two numbers was greater than 0, that indicated that they shared
a factor, and therefore were not relatively prime. Otherwise, they were relatively prime
- Then, I copied the columns that did the job for
those numbers, such that I could test several thousand such pairs in the same
worksheet (Case 1 tested 1152 pairs of numbers, while Case 2 tested 2304 pairs).
- I counted up the number of pairs that were
relatively prime, and divided that into the number of pairs tested.
- Then, I compared that to the value of 6/pi**2.
- With a little algebra, that could be used to
estimate the value of pi, via this purely statistical number theory method.
- Then, I repeated that process one hundred times,
recording the results, and graphing them (Case 1).
- I repeated the process, doubling the number of
pairs tested, and recorded those results (Case 2).
· Yes, I know this model could have been made a lot
more efficient (e.g. no point testing all the numbers between 1 and 100), but I
just wanted to get some quick results for Pi Day, so I didn’t slave over the
details.
Below are
the graphs of the results:
Case 1 - In
this case, the mean value computed for pi over the 100 runs was 3.135 (to three
decimal places), with a standard deviation of .040 and a median of 3.131. The graphs is “sort-of” normal, but with a
lot of deviation from a Gaussian.
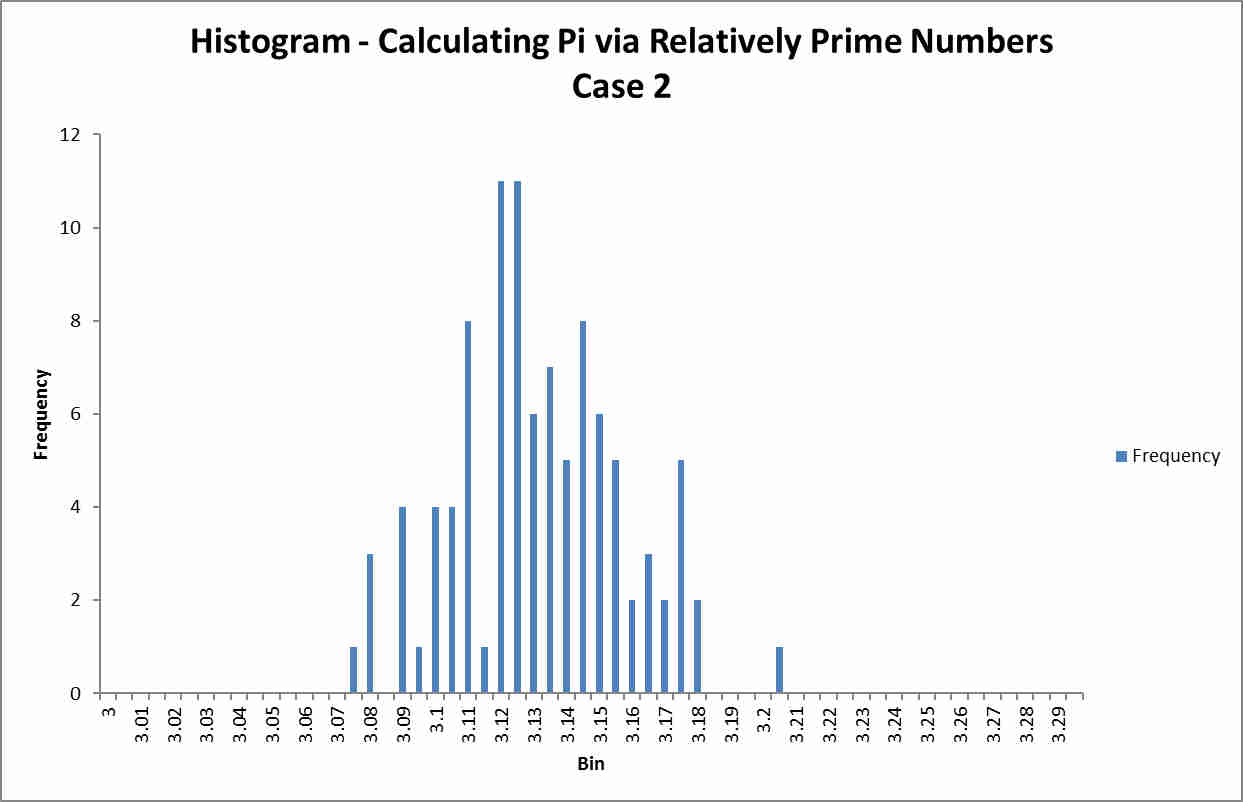
Case 2 - In
this case, the mean value computed for pi over the 100 runs was 3.129 (to three
decimal places), with a standard deviation of .026 and a median of 3.127. Again, the graph is “sort-of” normal, but
with a lot of deviation from a Gaussian.
As you
can see, the histogram is tighter in case 2, reflecting the fact that there
were twice as many pairwise comparisons for each run.
It is
interesting that both runs underestimated the true value of pi, by about 0.3%
in one case and about 0.5% in the other case.
I don’t know if that is just a fluke, or if there is some subtle bug,
either in my implementation or in Excel’s random number generator. I have often had my doubts about the latter.
At any rate, it seems clear that this
method converges slowly to the true value of pi. In the days before computers, it would have
been quite a challenge to generate the data.
Now, though, one could run a test like this a few million times (e.g. in
Python or SPSS) and probably get quite a reasonable estimate for pi. But it is interesting that pi can be
estimated from a method that has no geometrical basis, at all.
And here’s a picture of one of my wife’s
(and SF writer) Pi Day pies – pumpkin pie, which is scrumptious with whipped
cream and a great favorite of my data warehouse and data science colleagues at
the office.
Sources:
Recreations
in the Theory of Numbers, Albert Beiler, Dover
So, now
that you have done some math, you should read a science fiction book, or even
better, a whole series. Book 1 of the
Witches’ Stones series even includes a reference to pi.:
Kati of
Terra
How about trying Kati of Terra,
the 3-novel story of a feisty young Earth woman, making her way in that big,
bad, beautiful universe out there.
The Witches’ Stones
Or, you might
prefer, the trilogy of the Witches’ Stones (they’re psychic aliens, not actual
witches), which follows the interactions of a future Earth confederation, an
opposing galactic power, and the Witches of Kordea. It features Sarah Mackenzie, another feisty
young Earth woman (they’re the most interesting type – the novelist who wrote
the books is pretty feisty, too).
“A geophysical crew went into the Canadian
north. There were some regrettable accidents among a few ex-military who had
become geophysical contractors after their service in the forces. A young man
and young woman went temporarily mad from the stress of seeing that. They
imagined things, terrible things. But both are known to have vivid
imaginations; we have childhood records to verify that. It was all very sad.
That’s the official story.”
In the field known as Astrobiology, there
is a research program called SETI, The Search for Extraterrestrial
Intelligence. At the heart of SETI, there is a mystery known as The Great
Silence, or The Fermi Paradox, named after the famous physicist Enrico Fermi.
Essentially, he asked “If they exist, where are they?”.
Some quite cogent arguments maintain that if there was extraterrestrial
intelligence, they should have visited the Earth by now. This story, a bit
tongue in cheek, gives a fictional account of one explanation for The Great
Silence, known as The Zoo Hypothesis. Are we a protected species, in a Cosmic
Zoo? If so, how did this come about? Read on, for one possible solution to The
Fermi Paradox.
The short story is about 6300 words, or about half an hour at typical reading
speeds.